Market Analysis
Beyond USDA CDL: Why the World Needs an Independent Global Crop Classification Layer
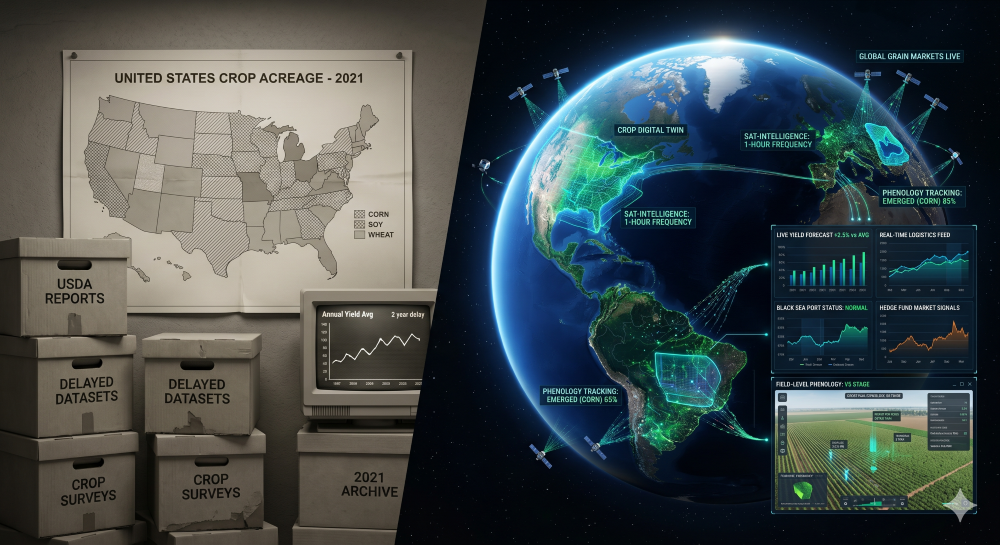
The Map That Taught America to See Its Cropland
In 1997, the USDA National Agricultural Statistics Service began publishing what would become one of the most quietly important agricultural datasets in the world. The Cropland Data Layer, or CDL, is an annual, raster, geo-referenced, crop-specific land cover map of the United States, built from satellite imagery and agricultural ground reference data. It started with limited coverage. By 2008 it spanned the entire continental U.S. By 2024 it was running at 10-meter resolution. By February 2026, the 2025 CDL was live, classified using a random forest model in Google Earth Engine on harmonized Sentinel-2 and Landsat surface reflectance.
That is a remarkable institutional achievement. And it is also, increasingly, the ceiling rather than the frontier.
For the U.S., CDL is foundational infrastructure. For global commodity markets, the equivalent layer does not exist - and that absence is no longer an academic problem. It is a structural gap in how the world prices supply.
What the Cropland Data Layer Actually Is
CDL is a pixel-by-pixel classification of what was growing on every parcel of the continental United States in a given year. Corn, soybeans, winter wheat, cotton, sorghum, rice, and over a hundred other categories, each assigned to a 10-meter pixel using satellite reflectance signatures, Farm Service Agency grower-reported field data, and ancillary inputs like the National Land Cover Database and digital elevation models.
It is not a yield product. It is not a forecast. It is a backward-looking inventory: this is what was planted, where, last season. Released roughly four to six months after harvest, it becomes the de facto reference layer for everything downstream - acreage estimation, crop rotation analysis, conservation monitoring, insurance analytics, and the academic research pipeline that feeds the next generation of agricultural models.
The architecture is mature. The classification confidence layer tells users, pixel by pixel, how certain the model is. The cultivated layer rolls up five years of CDL into a stable cropland mask. The crop frequency layers track how often a given pixel was corn or soybeans across the historical record. CropScape, the public-facing visualizer, makes all of it accessible to anyone with a browser.
Why CDL Matters So Much
The reason CDL became indispensable is not that it is the most accurate crop map ever built. It is that it is shared, standardized, and authoritative. When a USDA economist, a university researcher, an insurance underwriter, and a hedge fund analyst all reference the same crop type layer, downstream analysis becomes comparable, reproducible, and defensible. That is the institutional value of CDL: it gave U.S. agriculture a common visual baseline.
It also enabled an entire layer of analytics that would otherwise be impossible. Crop rotation studies depend on multi-year CDL stacks. County-level acreage estimation leans on CDL as a regression input alongside survey data. Conservation programs use it to verify cover crop adoption and grassland conversion. The economic value of having one trusted classification layer, updated annually and free to redistribute, is hard to overstate.
Where CDL Stops
But CDL was built for a specific job, and that job is not commodity intelligence. Three structural limitations matter for any market participant who tries to use it as a trading input.
It is annual, not in-season. The 2025 CDL was released in February 2026 - useful for retrospective analysis, useless for trading the 2025 harvest. By the time CDL ratifies what was actually planted, the price discovery has already happened.
It is national, not global. CDL covers the United States. It does not cover Brazil, Argentina, Ukraine, Russia, China, India, or any of the other production regions that move global commodity prices. As we explored in Mapping the World's Major Crops, the technical challenge of crop classification is not the bottleneck. The institutional one is.
It is dependent on a single agency. CDL is produced by USDA NASS. Its methodology, release schedule, and continuity are tied to a single national statistical agency. For institutional users who need globally consistent, vendor-independent intelligence, that is a single point of failure - and as we have documented in USDA Yield Forecasts Are Systemically Wrong, even the data we do get from federal sources carries structural disadvantages that show up directly in market outcomes.
The USDA Cropland Data Layer (CDL) is generally considered a high-accuracy dataset (>80%), but accuracy varies significantly by crop, region, and year. In some cases, reported accuracies can fall below this level, leading to discrepancies between CDL-derived acreage and official USDA statistics. [usgs.gov]
The Global Gap
The honest framing is this: the rest of the world has no CDL. There is no Argentinian CDL, no Brazilian CDL, no Black Sea CDL with the same institutional weight, public access, and continuity. There are national efforts, regional efforts, and academic projects, but no operational equivalent that the global market can lean on the way U.S. participants lean on CDL.
The most credible attempt to close this gap is the European Space Agency's WorldCereal project, which has built the first open-access global cropland and crop type maps at 10-meter resolution, with the public system now live and free to use. WorldCereal is genuinely impressive work. It is also, by design, a research and development initiative - its current product collection covers 2021, with seasonal expansion ongoing through 2026, and its core mandate is to demonstrate feasibility and support food security policy, not to deliver trader-grade intelligence on a continuous basis.
That distinction matters. A research initiative producing a global crop map for 2021 in 2024 is a scientific achievement. A market participant trying to position around the 2026 Brazilian soybean crop needs something different: continuous, in-season, independently produced classification at field-level resolution, available for every major production region simultaneously.
The resolution gap between U.S. and global crop mapping has effectively closed. The cadence gap, the independence gap, and the trader-readiness gap have not.
USDA CDL vs. SatYield Crop Classification
The contrast between an institutional reference layer and an operational intelligence layer is worth making concrete.
From Crop Maps to Crop Intelligence
The frontier is not a better CDL. It is a different category of product entirely - one that treats crop classification as the base layer beneath continuous, model-ready supply intelligence rather than the deliverable itself.
That shift is what we have argued matters most in From Public Data to Tradable Supply Signals: the value is not in the raw classification, it is in what the classification enables when fused with phenological state, biophysical stress signals, and yield formation tracked continuously through the season. A crop map is a noun. Crop intelligence is a verb.
For institutional commodity markets, the requirements are specific. The classification has to be global, because supply is global. It has to be in-season, because price discovery is continuous. It has to be independent, because reliance on a single national agency creates concentration risk. It has to be model-ready, because quantitative researchers need features, not GIS files. And it has to be the foundation layer for downstream signals - acreage divergence versus consensus, yield formation versus biological potential, supply forecast revisions versus official reports - rather than the end product.
That is what the SatYield Engine is built to do, and it is the direction the entire category is moving. CDL did something profound for U.S. agriculture: it created a shared truth layer. The next chapter is creating that layer for global markets, with the cadence and independence the institutional audience actually needs.
The Bottom Line
The Cropland Data Layer is a remarkable piece of public infrastructure. Anyone working in U.S. agriculture, agricultural research, or land use analytics owes a debt to NASS for building and maintaining it for nearly three decades. Respect for what CDL accomplished should be the starting point of any serious conversation about what comes next.
But what comes next is not another CDL. It is an independent, continuous, global classification layer purpose-built for the markets and decisions that depend on knowing what is in the ground - now, everywhere, with the resolution and reliability institutional users require. The U.S. has its base layer. The world is still waiting for its own.
more from the blog
